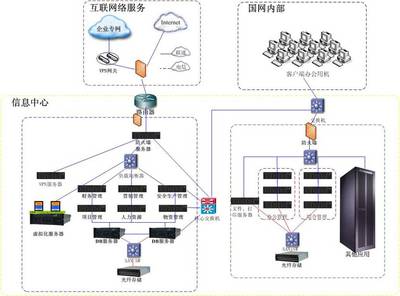
Netflix如何在上萬臺機器中管理微服務 史上最全信息管理服務解析
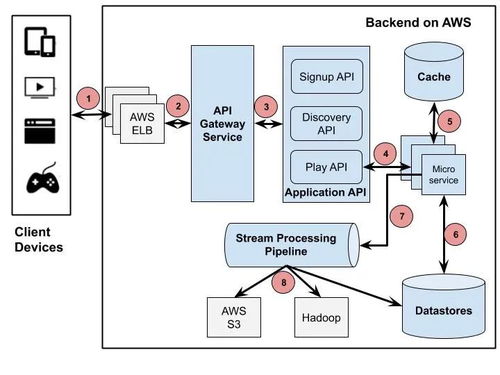
Netflix作為全球領先的流媒體服務提供商,其技術架構以微服務為核心,支撐著全球數(shù)億用戶的觀影需求。面對上萬臺分布式機器的復雜環(huán)境,Netflix構建了一套高度自動化、可擴展且極具韌性的微服務管理體系。本文將深入剖析其核心信息管理服務,揭示其背后高效運轉的秘密。
一、核心基石:Netflix自研的微服務平臺
Netflix的微服務管理并非依賴于單一工具,而是一個由多個自研核心組件構成的生態(tài)系統(tǒng),其中最為關鍵的是Netflix OSS(Open Source Software)套件。這些組件協(xié)同工作,確保服務在上萬臺機器間無縫運行。
- Eureka:服務注冊與發(fā)現(xiàn)
- 角色:微服務架構的“電話簿”。每個微服務實例啟動時,都會向Eureka服務器注冊自己的網絡位置(如IP和端口)。服務消費者通過查詢Eureka來動態(tài)發(fā)現(xiàn)所需服務的可用實例,而無需硬編碼服務地址。
- 在上萬臺機器中的管理:Eureka采用對等復制架構,多個Eureka服務器相互注冊,形成集群。即使部分服務器宕機,注冊表信息依然能在集群中保持同步,確保了高可用性。服務實例通過發(fā)送心跳來維持其“健康”狀態(tài),失效實例會被自動剔除。
- Ribbon:客戶端負載均衡
- 角色:基于客戶端的智能負載均衡器。當服務消費者通過Eureka獲取到某個服務的多個實例列表后,Ribbon會介入,根據配置的策略(如輪詢、隨機、響應時間加權等)選擇一個實例發(fā)起請求。
- 在上萬臺機器中的管理:將負載均衡邏輯從中心化的負載均衡器(如Nginx)轉移到每個客戶端,消除了單點故障和性能瓶頸,使得流量分發(fā)更加分散和高效,完美適配大規(guī)模機器集群。
- Hystrix:熔斷與容錯
- 角色:分布式系統(tǒng)的“斷路器”。當某個微服務調用失敗(如超時、異常)達到一定閾值時,Hystrix會快速失敗(熔斷),阻止連鎖故障在整個系統(tǒng)中蔓延,并可提供降級邏輯(如返回緩存數(shù)據或默認值)。
- 在上萬臺機器中的管理:在龐大的服務網格中,局部故障是常態(tài)。Hystrix為每個依賴服務(如上萬次調用中的某個數(shù)據庫服務)維護獨立的線程池或信號量隔離,確保一個服務的延遲或失敗不會拖垮整個應用。它通過實時的指標流(Metrics Stream)幫助運維人員全局監(jiān)控系統(tǒng)健康狀況。
- Zuul:動態(tài)路由與網關
- 角色:系統(tǒng)的“前門”和“智能路由器”。所有外部請求首先到達Zuul網關,它可以進行身份驗證、監(jiān)控、動態(tài)路由、壓力測試、安全防護等。
- 在上萬臺機器中的管理:Zuul作為邊緣服務,能夠將流量動態(tài)路由到后臺上萬臺機器中的具體服務實例。它與Eureka集成,自動感知服務實例的變化,實現(xiàn)無縫的擴容和故障轉移。
二、協(xié)調與配置:確保全局一致性與敏捷性
管理上萬臺機器,意味著需要高效地協(xié)調服務部署和統(tǒng)一管理配置。
- Spinnaker:持續(xù)交付平臺
- 角色:Netflix開源的多云持續(xù)交付平臺,負責微服務的構建、測試、部署和發(fā)布全流程。
- 在上萬臺機器中的管理:Spinnaker支持復雜的部署策略,如藍綠部署、金絲雀發(fā)布和滾動更新。它可以直接與云供應商(如AWS)的API交互,在上萬臺虛擬機或容器中自動化執(zhí)行這些策略,確保新服務版本能夠安全、可控地滾動到整個集群,并能在出現(xiàn)問題時快速回滾。
- Archaius:動態(tài)配置管理
- 角色:Netflix的配置管理客戶端庫,支持動態(tài)、類型化的屬性。
- 在上萬臺機器中的管理:微服務的配置(如數(shù)據庫連接、功能開關)需要能夠在不重啟服務的情況下動態(tài)更改。Archaius與配置源(如數(shù)據庫、文件系統(tǒng))集成,并提供了高效的輪詢機制,使得運行在上萬臺機器上的所有服務實例能近乎實時地獲取最新的配置變更,實現(xiàn)全局配置的統(tǒng)一管理和快速生效。
三、可觀察性與監(jiān)控:洞察每一臺機器的脈搏
沒有監(jiān)控,管理就無從談起。Netflix建立了全面的可觀察性體系。
- Atlas:近實時運營監(jiān)控平臺
- 角色:Netflix自研的時序數(shù)據庫和監(jiān)控系統(tǒng),用于存儲、索引和查詢海量的時間序列指標數(shù)據。
- 在上萬臺機器中的管理:每個微服務、每個容器、每臺主機都會每秒向Atlas發(fā)送數(shù)十甚至上百個指標(如CPU、內存、請求量、延遲、錯誤率)。Atlas能夠高效處理這每秒數(shù)十億的數(shù)據點,并提供強大的查詢語言,讓工程師能夠快速定位從全局業(yè)務指標到單臺機器性能的任何問題。
- Vector:實例性能監(jiān)控代理
- 角色:部署在每臺EC2實例上的輕量級代理,負責收集主機級別的系統(tǒng)指標(如CPU、內存、磁盤、網絡)。
- 在上萬臺機器中的管理:Vector作為統(tǒng)一的數(shù)據采集器,確保了所有機器監(jiān)控數(shù)據格式和上報方式的一致性,簡化了大規(guī)模基礎設施的監(jiān)控數(shù)據收集工作流。
四、通信與韌性:服務間高效可靠的對話
在龐大的服務網絡中,通信的效率與可靠性至關重要。
- gRPC與RESTful API:Netflix內部廣泛使用基于HTTP/2的gRPC框架進行高性能、低延遲的服務間通信,同時也大量使用RESTful API。統(tǒng)一的標準簡化了服務間的集成。
- 自適應并發(fā)限制與優(yōu)先級排隊:Netflix開發(fā)了如自適應并發(fā)限制等機制,系統(tǒng)能夠根據下游服務的健康狀態(tài)和自身容量,動態(tài)調整發(fā)出的請求數(shù)量,防止過載,這在上萬臺機器同時發(fā)起請求的場景下尤為重要。
五、數(shù)據管理與緩存:應對海量請求
- EVCache:分布式內存緩存
- 角色:Netflix基于Memcached構建的分布式緩存服務,主要用于會話存儲和個性化推薦等熱數(shù)據緩存。
- 在上萬臺機器中的管理:EVCache客戶端與部署在多個AWS可用區(qū)的Memcached集群交互,通過一致性哈希將數(shù)據分布到上千個緩存節(jié)點上。它提供了跨區(qū)域復制功能,確保即使整個可用區(qū)宕機,數(shù)據依然可用,極大提升了讀性能和數(shù)據韌性。
文化、自動化與持續(xù)演進
Netflix能在上萬臺機器中成功管理微服務,除了上述強大的技術工具棧,更深層的原因在于其工程師文化:
- 自由度與責任:賦予團隊對服務的完全所有權(構建、運行、維護)。
- 混沌工程:通過如Chaos Monkey(隨機終止生產環(huán)境實例)等工具主動注入故障,驗證系統(tǒng)的韌性,確保服務能經受住真實世界中任何單臺甚至多臺機器失效的考驗。
- 全自動化:從部署、監(jiān)控到故障響應,盡可能減少人工干預。
這套以Netflix OSS為核心,結合強大的內部平臺、全面的監(jiān)控和先進的工程實踐所構成的“信息管理服務體系”,使得Netflix的微服務架構不僅能夠支撐驚人的規(guī)模,更具備了應對變化與故障的卓越韌性,堪稱分布式系統(tǒng)管理的典范。
如若轉載,請注明出處:http://www.jqjsq.cn/product/82.html
更新時間:2026-05-02 03:00:06